【功能测试】 selenium的基本使用

前言
在处理大量数据录入或从网页提取信息的任务时,传统的手动输入方法不仅效率低下,而且容易出错。因此,有必要采用自动化技术来简化这一过程。
Selenium
作为一种网页自动化测试工具,提供了一套完整的解决方案,能够模拟用户在浏览器中的操作,实现网页数据的自动化输入和提取
Selenium的核心功能在于其能够模拟用户行为,如点击按钮、输入文本等,从而实现对Web界面的自动化交互。此外,Selenium还能够从Web界面中提取信息,例如火车票务信息、招聘网站职位信息、财经网站股票价格信息等,这些信息随后可以被程序进一步分析和处理。
总而言之,Selenium可以让我们用程序来从网上大量的输入信息和获取信息的自动化的能力,从而显著提升了工作效率。
而在使用selenium之前,我们需要配置对应的环境:
Python解释器 pycharm集成开发环境 与selenium自动化测试工具
![]()
开始使用selenium
在进行网页自动化操作时,必须借助浏览器厂商提供配套的WebDriver(浏览器驱动)来控制浏览器。为了实现这一目标,Python环境中需要安装Selenium库,该库提供了调用WebDriver的接口,以便发送自动化指令。
在使用WebDriver之前,必须先导入Selenium库中的WebDriver模块。以下是导入WebDriver模块的代码示例:
如果我们添加了chrome,chrome配套的webdriver与python的环境变量path,则可以这么做:
from selenium import wedriver
#这段代码则是从selenium库中调用webdriver文件
随后,通过创建WebDriver实例来初始化浏览器驱动,并将其实例化对象赋值给driver变量
driver = webdriver.Chrome()
这会把webdriver.Chrome()放在driver变量里,以便后续代码中方便地引用和操作浏览器。
但是(西卡西)
在高版本的Selenium中,我们发现存在一个自动化下载并加载WebDriver的问题:
具体而言,每次启动Selenium或者清除缓存后,Selenium会自动检查WebDriver的更新状态,并在必要时重新下载,这一过程可能会因网络延迟而导致启动浏览器的时间显著延长。
为了避免这一问题,可以采用Selenium提供的Service类来手动加载WebDriver,从而避免每次启动时自动下载更新。
参照以下代码用service加载驱动即可
1 | from selenium import webdriver |
第一章 元素的定位
什么是元素的定位
元素定位是网页自动化测试中的一项关键技术,它允许自动化工具(例如Selenium)在复杂的网页结构中精确识别并操作特定的HTML元素。
这一过程类似于在复杂页面中精确找到一个目标。通过元素定位,自动化脚本能够与网页上的按钮、输入框、链接等元素进行交互,执行如点击、输入等操作。
因此,我们必须要让浏览器 先找到元素,然后,才能操作元素。
基本元素定位
在Selenium中,元素的选择依赖于selenium库的By类,因此需要在使用前调用selenium库,代码如下
from selenium.webdriver.common.by import By
通过id定位元素
以百度一下,你就知道首页的搜索框为例
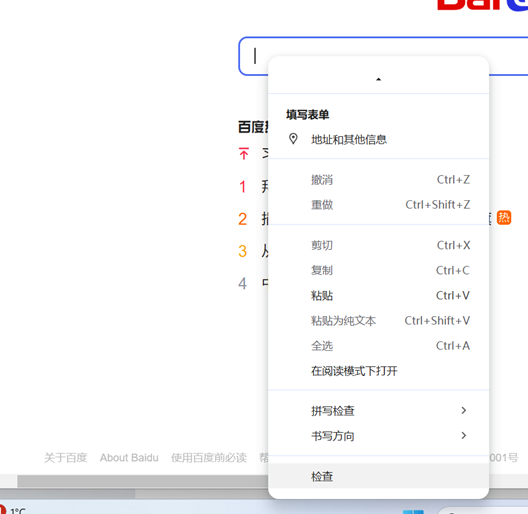
通过浏览器的开发者工具检查元素,可以发现输入框的input标签具有一个特定的ID值kw。

ID属性在HTML中用于唯一标识一个元素。
利用这一属性,可以通过以下代码精确定位到该输入框,并在其中输入文本”selenium”:
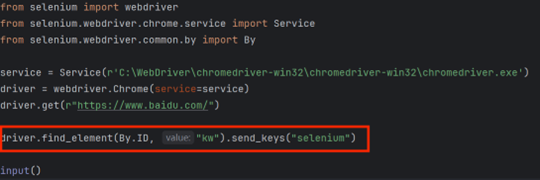
其中,
driver是webdriver.Chrome(service=service)实例化的对象,它提供了操作浏览器的方法,如打开网址、选择界面元素等。find_element方法则用于根据提供的定位器(如ID)查找元素,而send_keys方法用于在找到的元素上执行键盘输入操作。
此外,如今的selenium4虽然支持曾经selenium3的语法但极为不赞成使用
1 | # selenium3的定位元素语法 |
因此,我们要使用下面的格式
1 | # selenium4的定位元素语法 |
通过name,class定位元素
除了ID,元素的name和class属性也常用于定位。
还是以百度搜索栏为例,input标签内除了有id属性,还有class,name等其他属性。

而name,class的定位在find_element中同样常用且重要,他们的语法则是这样:
1 | # id 定位 |
这三个代码都能定位到输入框并且输入selenium
在某些情况下,一个元素可能具有多个class类型,这些类型通过空格分隔。

例如,在新浪网的一个元素可能同时具有top-nav-wrap和top-nav-wrap-fix两个类名。
可以通过以下方式分别定位这些类名对应的元素:
1 | find_elements(By.CLASS_NAME,'top-nav-wrap') |
需要注意的是,不能将两个类名合并为一个字符串来定位元素,如:
1 | # 错误示例 |
通过link_text定位元素
在Selenium中,link_text是一种用于定位网页中超链接元素(<a>标签)的方法。通过匹配链接的完整文本内容,可以快速找到对应的元素。
以百度首页的左上角的”新闻”链接的标签举例

可以发现这个超链接的文本内容是”新闻”,因此,如果想使用link_text方法定位这个元素,具体代码如下
[driver.find_element(By.LINK_TEXT, "新闻").click()]{.mark}
需要注意的是,link_text定位要求提供的文本与页面上的文本完全一致,否则无法定位到元素
通过partial_link_text定位元素
partial_link_text 与link_text
类似,但它允许根据文本内容的一部分来定位超链接元素,这种定位类似于模糊搜索。这在链接文本特别长或者动态链接生成时非常实用。
还是以新闻超链接举例:

我们可以用partial_link_text寻找”新”文本即可找到目标超链接
[driver.find_element(By.PARTIAL_LINK_TEXT, "新").click()]{.mark}
通过tag定位元素
在Selenium中,通过标签名(tag name)定位元素是一种常用的元素定位方法。这种方法适用于定位页面中具有相同标签名称的元素,如div、input等。
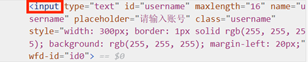
我们以 某个登录模块 为例
若要定位密码输入框,其标签名为input,我们可以通过以下代码实现:
driver.find_elements(By.TAG_NAME,"input")[1].send_keys("123456")
与之前的代码相比,此处使用了
find_elements(复数形式),并在send_keys前添加了索引[1]
复数元素定位
在页面中,名为input的标签往往不止一个,
比如举例的登陆模块,一共有三个input元素
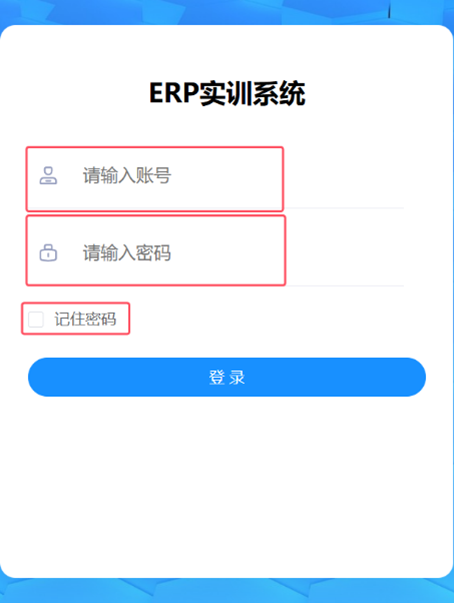
这三个input类型分别为
textpassword和一个checkbox
在使用**element_find选择的是符合条件的第一个元素,
如果没有符合条件的元素, 则会报错
在使用**element_finds选择的是符合条件的所有元素作为列表返回,如果没有符合条件的元素, 则会返回空列表
因此,要通过标签名定位到密码输入框,需要使用find_elements方法,并在后面添加索引[1],以选择返回列表中的第二个元素,即密码输入框。这种方法确保了在存在多个相同标签名元素的情况下,能够精确地定位到目标元素。
通过CSS selector,xpath定位元素
在Web自动化测试中,当目标元素缺乏唯一的ID或CLASS属性,或者存在具有相同ID、CLASS属性值的非目标元素时,传统的选择器可能无法精确定位。在这种情况下,CSS选择器(CSS selector)和XPath提供了更为灵活和强大的定位策略。这时候我们通常可以通过 CSS selector 与 XPath语法来选择元素
XPath
XPath(XML Path Language)是一种用于在 XML 文档中定位元素的语言,也被广泛应用于 HTML
页面中,特别是在网页自动化测试中用来定位和操作网页中的元素。
简单使用xpath
XPath通过构建路径表达式来选择HTML页面中的元素。它支持多种灵活的定位方式,包括基于层级关系、属性、文本内容等,这使得XPath在处理复杂的网页结构时显得尤为有效。接下来,我们将简要介绍如何简单地运用XPath。
通过浏览器的开发者工具定位到目标元素,在这里我们以登录页面的输入框为例:
右键该元素的代码段 > 复制 > 复制XPath
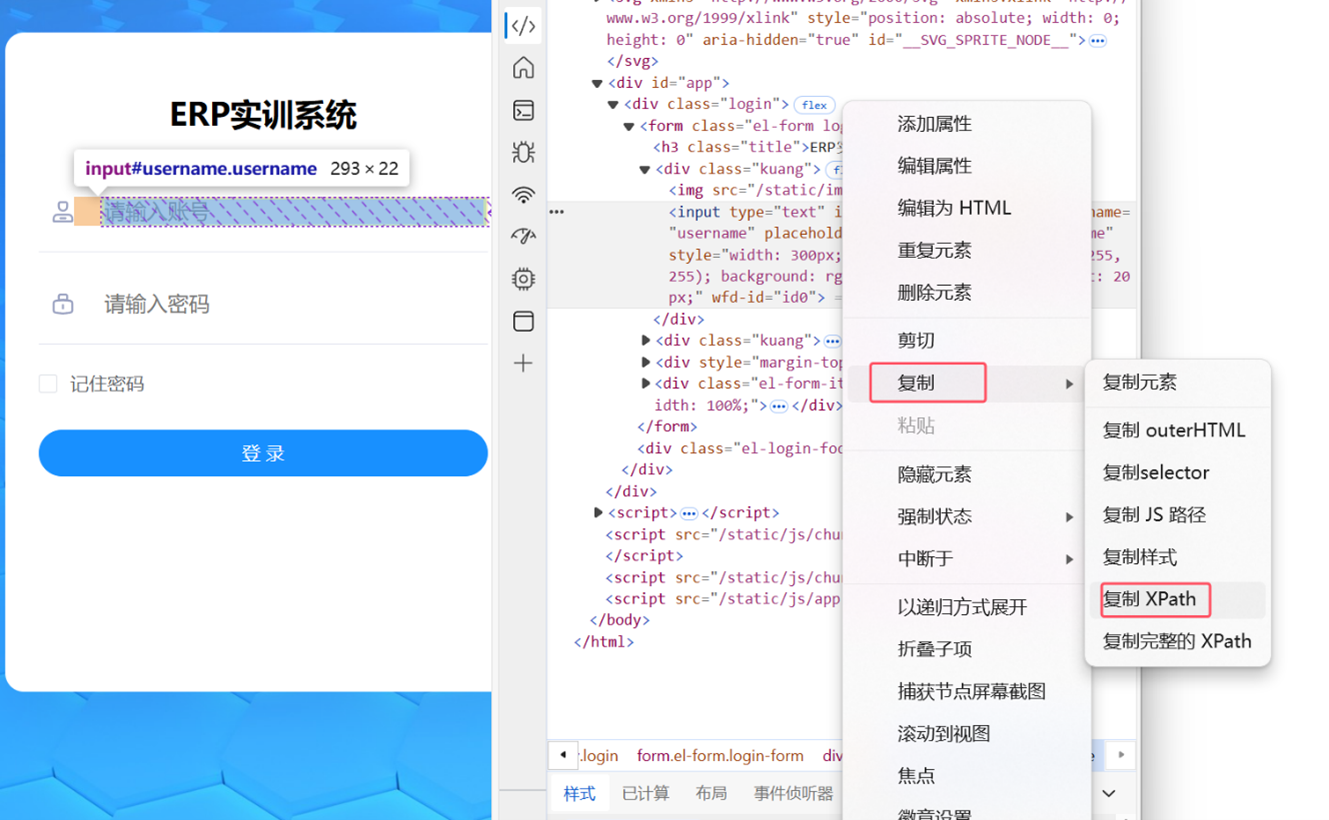
从目标元素的代码段复制xpath路径
将复制的XPath路径应用于Selenium脚本中,以实现对目标元素的精确定位和操作:
driver.find_element(By.XPATH,\'//\*\[@id=\"username\"\]\').send_keys(\'XTGLY\')
CSS selector
CSS Selector 是一种通过样式选择器规则,定位和操作 HTML
页面中特定元素的方法。最初用于前端样式设计,但因其高效、简洁的特点,也广泛应用于网页自动化测试工具(如 Selenium)中,以来快速定位目标元素。
简单使用CSS selector
与 XPath 相比,CSS Selector 的书写更直观且性能较高,虽然它不具备 XPath 灵活的层级和文本内容定位能力,但在绝大多数常见场景下,CSS Selector 已足够满足需求。
使用CSS Selector基本与XPath相同,唯一不同的是从复制XPath变成复制selector
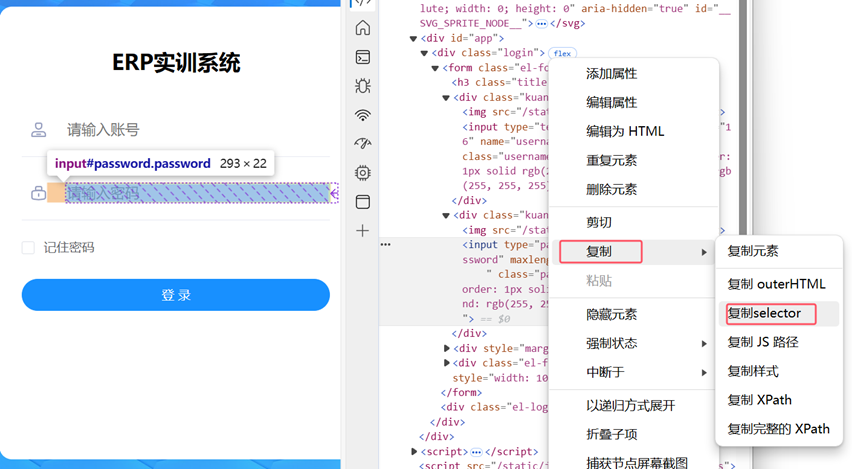
从目标元素的代码段复制CSS selector路径
driver.find_element(By.CSS_SELECTOR,\'#password\').send_keys(\"123456\")
通过这两种方法,CSS选择器和XPath为自动化测试提供了精确且强大的元素定位手段,使得测试脚本能够灵活地与网页元素进行交互。
第二章 三大时间等待
为什么要时间等待
在自动化测试过程中,由于外部环境的不可控性,页面或元素的加载时间可能会超出预期。若脚本在元素尚未完全加载时尝试进行操作,可能会导致操作失败。因此,引入等待机制是必要的,以确保测试脚本能够在元素准备就绪后再执行相应的操作。
对此,Selenium 提供了三种主要的等待机制:
强制等待、隐式等待和 显式等待
强制等待sleep()
强制等待是一种简单但不够灵活的等待方法,通过设置固定时间暂停脚本执行的一种方式,直到等待时间结束后才继续执行后续代码。
如果想要使用强制等待,我们需要导入time模块的sleep方法再去使用sleep()
1 | from time import sleep |
1 | import time |
两种使用强制等待的方法
可以预测,这种方法的不足之处在于:
不灵活性:如果页面加载时间超出了预设的等待时间,可能会导致元素定位失败。
效率问题:设置过长或过短的等待时间都会影响测试的效率。
隐式等待implicitly_wait()
隐式等待是 WebDriver 提供的一种全局等待机制,它允许在指定的时间内,如果元素未立即可用,WebDriver
会定期尝试查找元素,直到超时。该方法的设置是全局性的,适用于 WebDriver
实例的整个生命周期。
driver.implicitly_wait(10)
设置了隐式等待最大时间为10秒
然而,隐式等待存在以下限制:
全局性:隐式等待对所有元素查找操作都有效,但并非所有元素都需要等待。
条件限制:隐式等待只能检测元素是否存在于 HTML 源码中,而无法判断元素是否可点击或可见,这可能导致在尝试操作元素时抛出异常。
显示等待
显式等待提供了更精细的控制,允许测试者根据具体的条件来等待元素的可用性。使用显式等待时,通常需要导入
WebDriverWait 和 expected_conditions(简称 EC)模块。
WebDriverWait 的函数语法如下:
1 | from selenium.webdriver.support.ui import WebDriverWait # 导入 WebDriverWait |
导入了webdriverwait和ec模块
WebDriverWait 与EC
WebDriverWait 的函数语法如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions =None)
driver:指向浏览器驱动的 WebDriver 实例。
timeout:最大等待时间,以秒为单位。
poll_frequency(可选):检查条件的频率,默认为 0.5 秒。
ignored_exceptions(可选):在等待期间忽略的异常类型。
EC 提供了多种方法来定义等待条件,例如 EC.element_to_be_clickable
用于判断目标元素是否可点击。如果条件满足,则返回 True;否则,返回
False。
显示等待的使用方法
以下是一个显式等待的使用示例:
1 | wait = WebDriverWait(driver,timeout:10) |
在这个示例中,WebDriverWait 会在接下来的 10 秒内,每隔 0.5 秒检查一次,判断 ID 为 signIn 的按钮是否可点击。
如果条件满足,则执行 .click() 方法;
如果条件不满足,则抛出 TimeoutException 异常。
第三章 下拉滚动条与下拉框
下拉滚动条
为什么在sleenium中要使用下拉滚动条?
我们举一个例子
在新浪网的页面底部有一个文本为上海的超链接,点击它会跳转到新浪上海的主页。
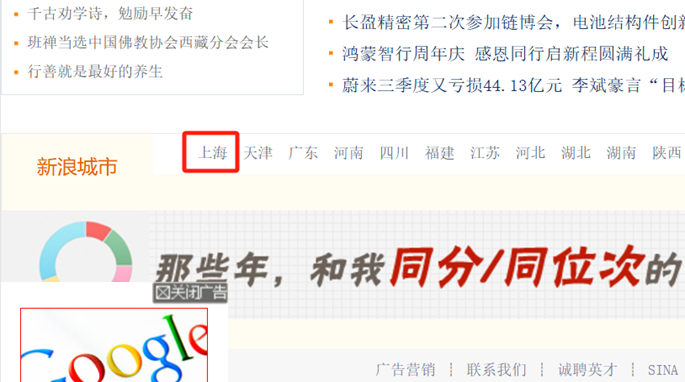
新浪网的页面底部,有一个名为”上海”的超链接

点进去会跳转到新浪上海的主页
如果我们尝试利用自动化脚本达成这种操作:
1 | driver.get('https://www.sina.com.cn/') |
则会抛出错误:

报错原因是element click intercepted
译为:元素的点击被拦截
这说明该元素无法 被点击,有可能是元素被遮挡不可见导致的
因此,我们需要移动滚动条到这个元素的位置后再完成点击。
并且这与我们模拟的用户操作是一样的 (滚动->点击
而在selenium 中,有两种方式可以滚动我们页面的滚动条
通过模拟用户操作按键达成滚动页面
![]()
- Title: 【功能测试】 selenium的基本使用
- Author: Yanxiao_xaya
- Created at : 2025-03-26 23:50:26
- Updated at : 2025-06-07 12:11:52
- Link: https://ssxaya.fun/2025/03/26/python_selenium/
- License: This work is licensed under CC BY-NC-SA 4.0.