【数据库】 DQL - 数据查询语言 Data Query Language (上)

DQL - 数据查询语言 Data Query Language (上)
本篇是以 MYSQL黑马程序员教学视频整理而成的笔记
1 | wget https://raw.githubusercontent.com/ssxaya/FileShare/main/mysqlDQL%E4%B8%8A.sql |
查询关键字 : SELECT
1 | # 语法 |
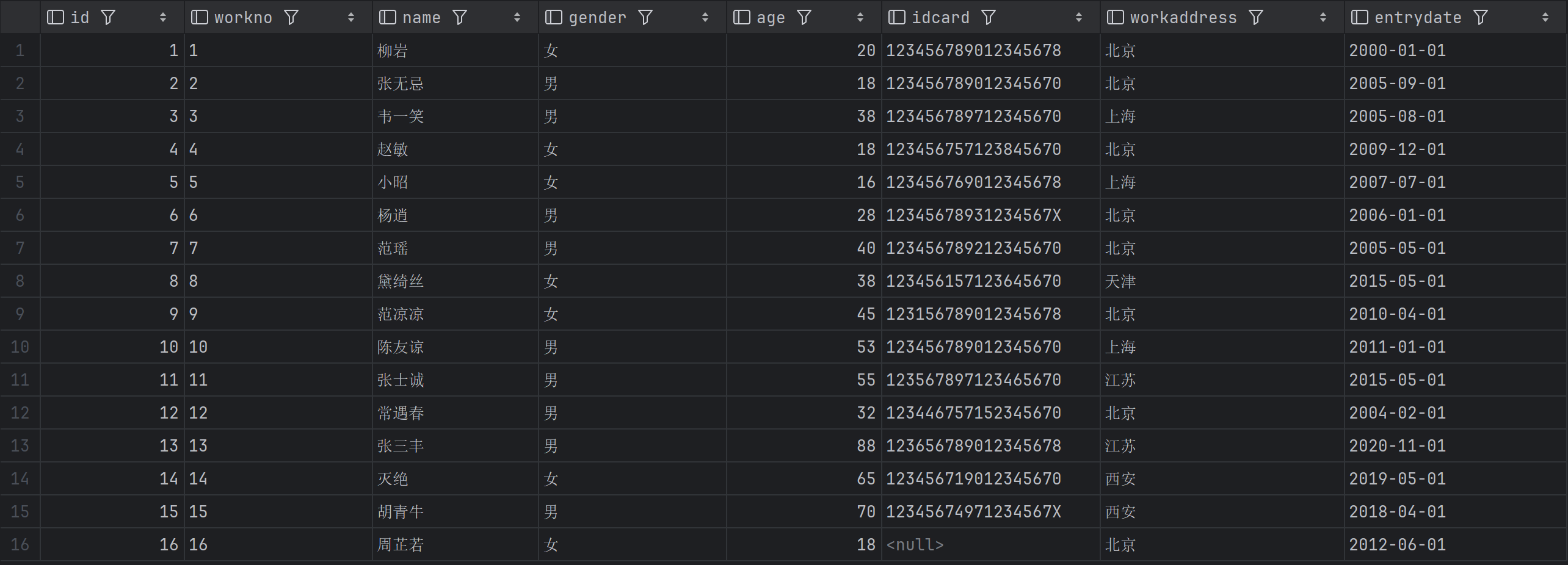
例表:
后文以此表为例进行举例
表名 emp
目录
[TOC]
![]()
[**SELECT**](# 基本查询 SELECT…FROM…)
[字段列表]
[**FROM**](# 基本查询 SELECT…FROM…)
[表名列表]
[**WHERE**](# 条件查询 WHERE)
[条件列表]
[**GROUP BY**](# 分组查询 GROUP BY & 聚合函数)
[分组字段列表]
[**HAVING**](# 分组查询 GROUP BY & 聚合函数)
[分组后条件列表]
[**ORDER BY**](# 排序查询 ORDER BY)
[排序字段列表]
[**LIMIT**](# 分页查询 LIMIT)
[分页参数]
基本查询 SELECT…FROM…
SELECT ... FROM ... 是 SQL 查询中最基本、最常用的语句结构,用于从数据库表中查询数据。
查询多个字段
语法:
SELECT 字段1、字段2、字段3... FROM 表名
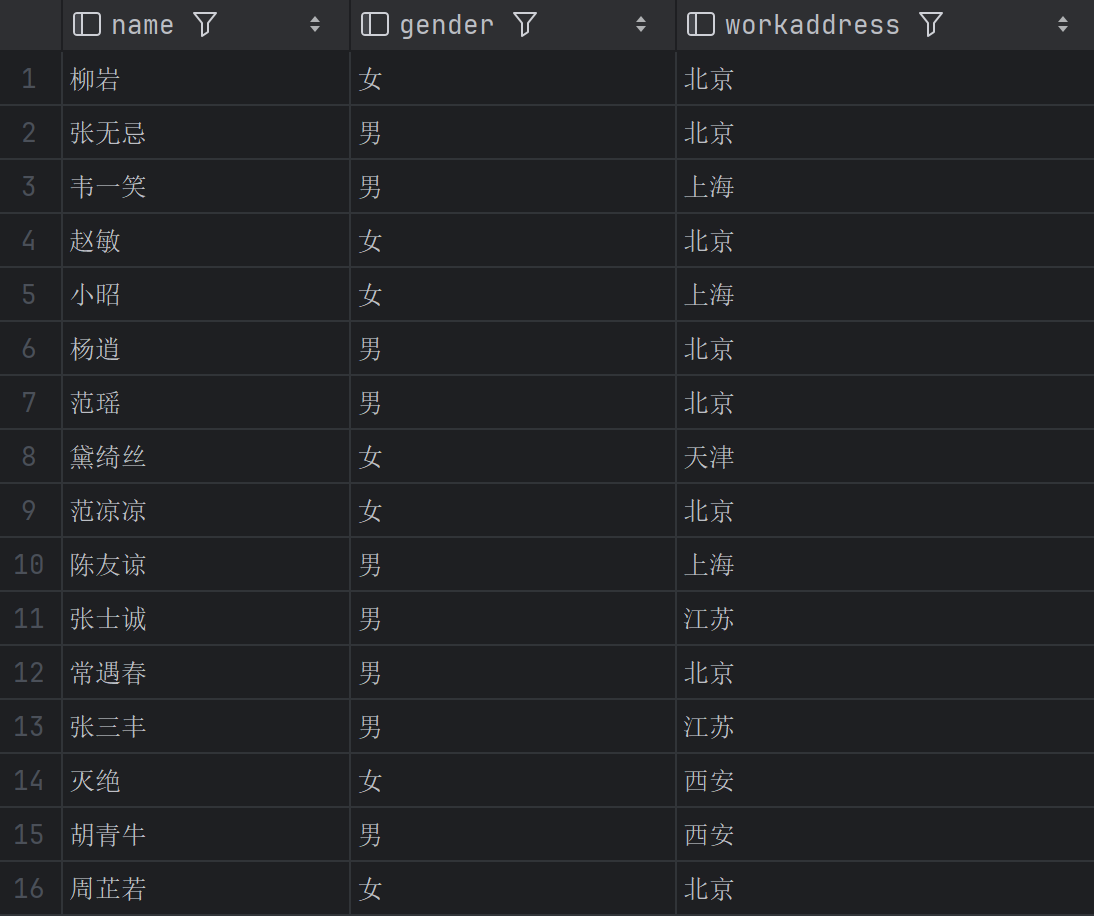
查询员工的姓名、性别和工作地址
1 | SELECT name, gender, workaddress |
这条语句选出了三列字段,适合只查看部分重要信息,而不是全表。
如果想要查询所有字段返回,可以使用通配符*
SELECT * FROM 表名返回表名中所有的字段
设置别名
在 SQL 中,AS 是用来为字段(列)或表设置**别名(alias)**的关键字。这样可以让查询结果更清晰、更易读,尤其在字段名复杂或有函数、计算时非常有用。
语法:
SELECT 字段名 AS 别名 FROM 表名;
或者省略as,直接空格也可以
SELECT 字段名 别名 FROM 表名;
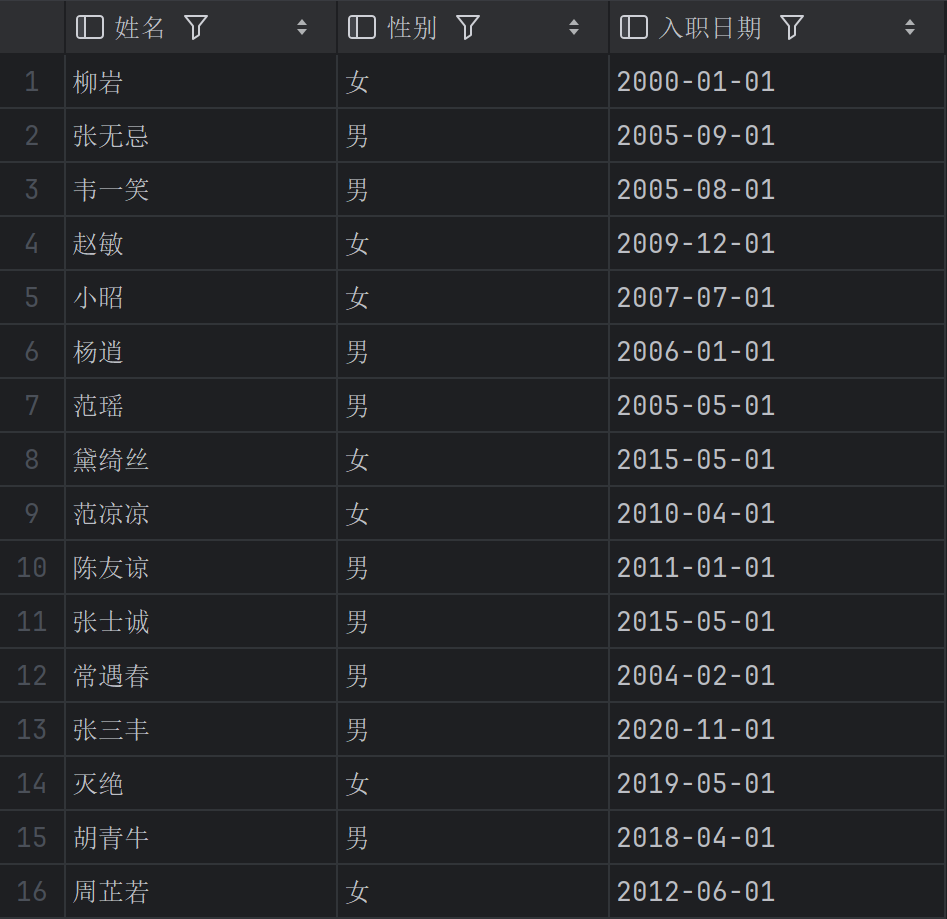
把列名和表名换成更易读的中文别名
1 | SELECT name AS 姓名, gender AS 性别, entrydate AS 入职日期 |
使用 AS 起别名可以美化输出结果,更利于报表阅读。
去重
在 SQL 中,DISTINCT 用于去重,即从查询结果中去除重复的记录,只保留唯一的值。
语法:
SELECT DISTINCT 列名 FROM 表名;
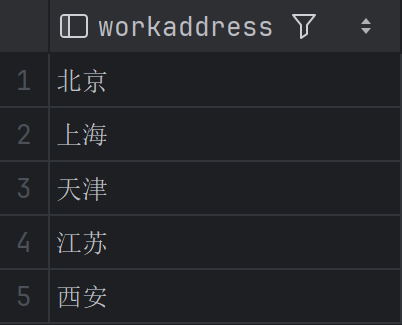
查询所有不重复的工作地址
1 | SELECT DISTINCT workaddress |
DISTINCT 去除了重复的 workaddress,只显示唯一城市。
条件查询 WHERE
WHERE 是 SQL 中非常常用的子句,用于指定查询条件,筛选出符合条件的记录。
语法:
SELECT 字段列表 FROM 表名 WHERE 条件列表
条件列表
比较运算符
| 运算符 | 含义 | 示例 | 说明 |
|---|---|---|---|
= |
等于 | age = 18 |
年龄等于 18 |
!= 或 <> |
不等于 | gender != '男' 或 gender <> '男' |
性别不是“男” |
> |
大于 | age > 30 |
年龄大于 30 |
< |
小于 | age < 25 |
年龄小于 25 |
>= |
大于等于 | age >= 18 |
年龄不小于 18 |
<= |
小于等于 | age <= 60 |
年龄不大于 60 |
BETWEEN ... AND ... |
在范围之间(含边界) | age BETWEEN 18 AND 30 |
年龄在 18 到 30 之间 |
IN (...) |
在多个值中 | workaddress IN ('北京', '上海') |
工作地址是“北京”或“上海” |
LIKE |
模糊匹配 | name LIKE '张%' |
名字以“张”开头 |
IS NULL |
是空值 | idcard IS NULL |
身份证为空 |
IS NOT NULL |
不是空值 | idcard IS NOT NULL |
身份证不为空 |
逻辑运算符
| 运算符 | 含义 | 示例 |
|---|---|---|
AND |
并且 | gender = '女' AND age < 25 |
OR |
或者 | workaddress = '北京' OR workaddress = '上海' |
NOT |
非 | NOT age = 18 或 age != 18 |
AND + OR |
组合逻辑 | gender = '男' AND (age > 30 OR workaddress = '上海') 使用括号避免歧义 |
例题
查询所有年龄大于等于 30 岁的男员工的信息
1 | SELECT * |

查询住在“北京”或“上海”的员工姓名、性别、工作地址
1 | SELECT name, gender, workaddress |
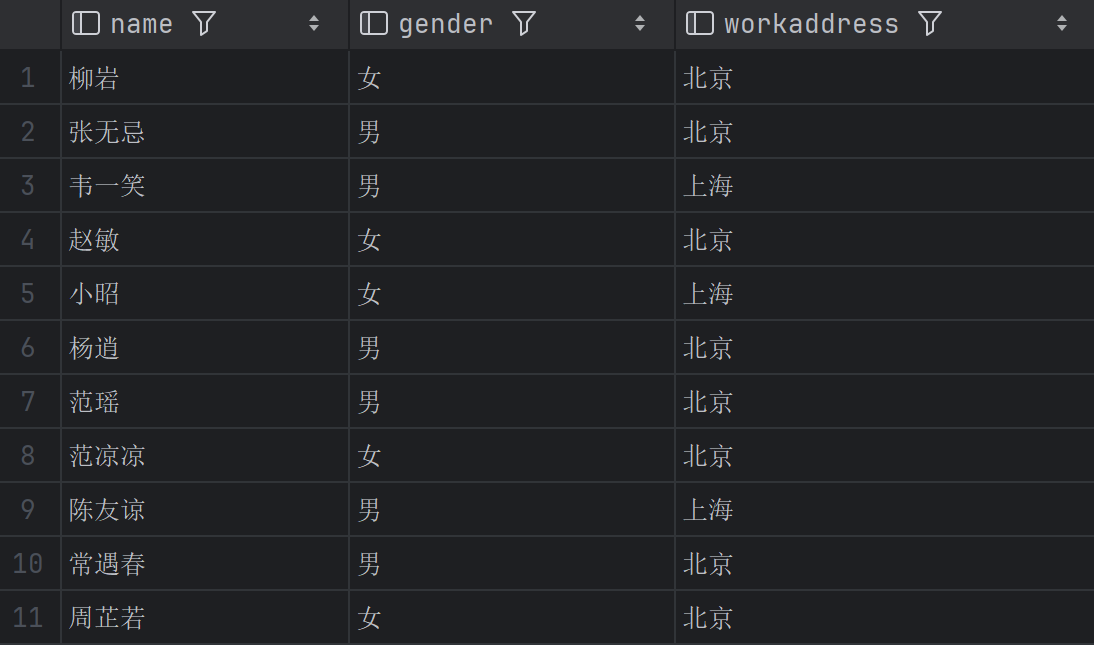
查询身份证号为空的女员工的姓名和入职时间
1 | SELECT name, entrydate |

查询所有名字中带“张”字的员工信息
1 | SELECT * |

查询年龄不是 18 岁,且工作地址不是“北京”的员工
1 | SELECT * |

查询年龄在 25 到 40 岁之间、并且身份证号不为空的男员工
1 | SELECT * |

查询所有姓名为“张无忌”的员工,如果他住在“上海”则不显示
1 | SELECT * |

查询不是“西安”工作地址,且年龄小于等于 35 岁或大于等于 60 岁的员工
1 | SELECT * |

分组查询 GROUP BY & 聚合函数
这两个概念常常配合使用,在 SQL 中用于 “按组统计” 的场景,比如:
查询每个城市有多少个员工、每个性别的平均年龄、每年入职的人数等等。
因此,我们先讲解聚合函数
聚合函数
聚合函数就是将一列数据作为一个整体,进行纵向计算,例如统计人数、求平均值、找最大最小值等。
你可以把聚合函数想象成一个“计算器”,它不是针对一行一行地处理数据,而是把一整列的数据当作一个整体来进行统计。
常见的聚合函数
| 函数名 | 中文含义 | 示例 | 说明 |
|---|---|---|---|
COUNT() |
计数 | COUNT(*) |
统计总行数(记录条数) |
SUM() |
求和 | SUM(age) |
统计某列所有数据的总和 |
AVG() |
平均值 | AVG(age) |
统计某列数据的平均值 |
MAX() |
最大值 | MAX(age) |
找出某列中最大的值 |
MIN() |
最小值 | MIN(age) |
找出某列中最小的值 |
例题
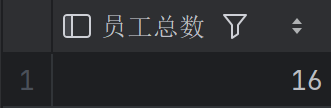
查询 emp 表中总共有多少名员工
1 | SELECT COUNT(*) AS 员工总数 |
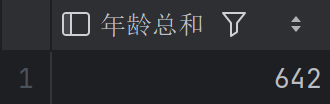
查询所有员工的年龄总和是多少
1 | SELECT SUM(age) AS 年龄总和 |
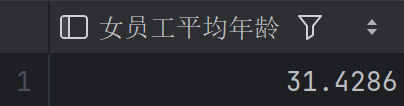
查询所有女员工的平均年龄是多少
1 | SELECT AVG(age) AS 女员工平均年龄 |
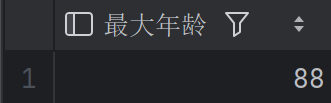
查询员工中最大的年龄是多少岁
1 | SELECT MAX(age) AS 最大年龄 |
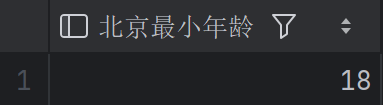
查询北京员工中最小的年龄是多少
1 | SELECT MIN(age) AS 北京最小年龄 |
分组查询 GROUP BY
分组查询 是指把数据库表中的数据,根据某个(或某些)字段的值分成不同的“组”,然后对每个组进行统计或汇总。在分组查询后,往往像组成一个”新的表”来进行展示(
GROUP BY就是按照某个字段的值是否相同,把数据分成一组一组的。同一个字段值的记录会被归为一组
每一组你都可以进行统计(用聚合函数,比如COUNT()、AVG()、SUM()等)
每一组的结果会形成结果表中的一行
语法:
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名 [HAVING 分组之后的条件];
WHERE 与 HAVING 的区别
- 执行时机不同:
WHERE是在数据分组GROUP BY之前执行的,用来筛选原始数据行;HAVING是在数据分组之后执行的,用来筛选分组后的结果。 - 判断条件不同:
WHERE中不能使用聚合函数,只能用普通的列和表达式做条件判断;HAVING可以使用聚合函数,基于统计结果来筛选分组。 - 作用对象不同:
WHERE作用于表中的每一条原始记录;HAVING作用于分组后的每一个组。 - 常见用途不同:
WHERE用来过滤行数据,比如“筛选年龄大于30岁的员工”;HAVING用来过滤分组,比如“筛选员工数大于5的部门”。
总而言之,WHERE 适用于对原始数据进行初步筛选,而 HAVING 则用于在分组和聚合之后,对分组结果进一步筛选。
例题
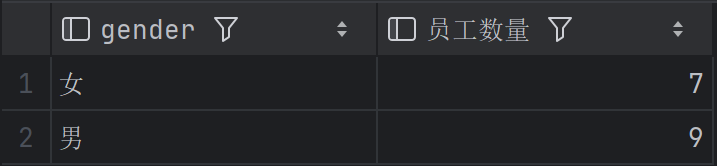
根据性别分组,统计男性员工和女性员工的数量
1 | SELECT gender, COUNT(*) AS 员工数量 |
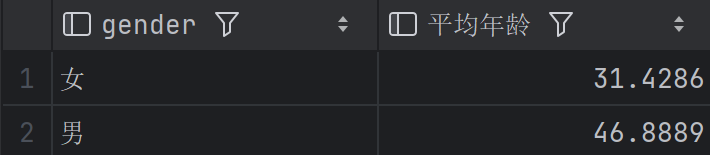
根据性别分组,统计男性员工和女性员工的平均年龄
1 | SELECT gender, AVG(age) AS 平均年龄 |
查询年龄小于45的员工,根据工作地址分组,获取员工数量大于等于3的工作地址
1 | SELECT workaddress, COUNT(*) AS 员工数量 |
- 从
emp表中找出年龄小于 45 岁的员工(WHERE)- 按照
workaddress(工作地址)对这些员工进行分组(GROUP BY)- 对每一组统计人数(
COUNT(*)),只保留人数不少于 3 的组(HAVING)- 最终展示符合条件的每个工作地址及其对应的员工数量(
SELECT)

排序查询 ORDER BY
ORDER BY 用来对查询结果进行排序,它是整个 SQL 的最后一步,即在 WHERE GROUP BY HAVING SELECT执行完后,在执行ORDER BY来决定显示顺序。
语法:
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1[ASC | DESC], 字段2 排序方式2[ASC | DESC];
ASC:升序(默认)DESC:降序
可以看出,
ORDER BY支持多字段排序。当第一个排序字段的值相同时,系统会继续根据第二个排序字段对结果进行进一步排序。
例题
查询所有员工的姓名和年龄,并按年龄从小到大排序
1 | SELECT name, age |
ORDER BY age ASC表示按照age升序排列。即:年龄越小越排前。其中ASC可以省略。
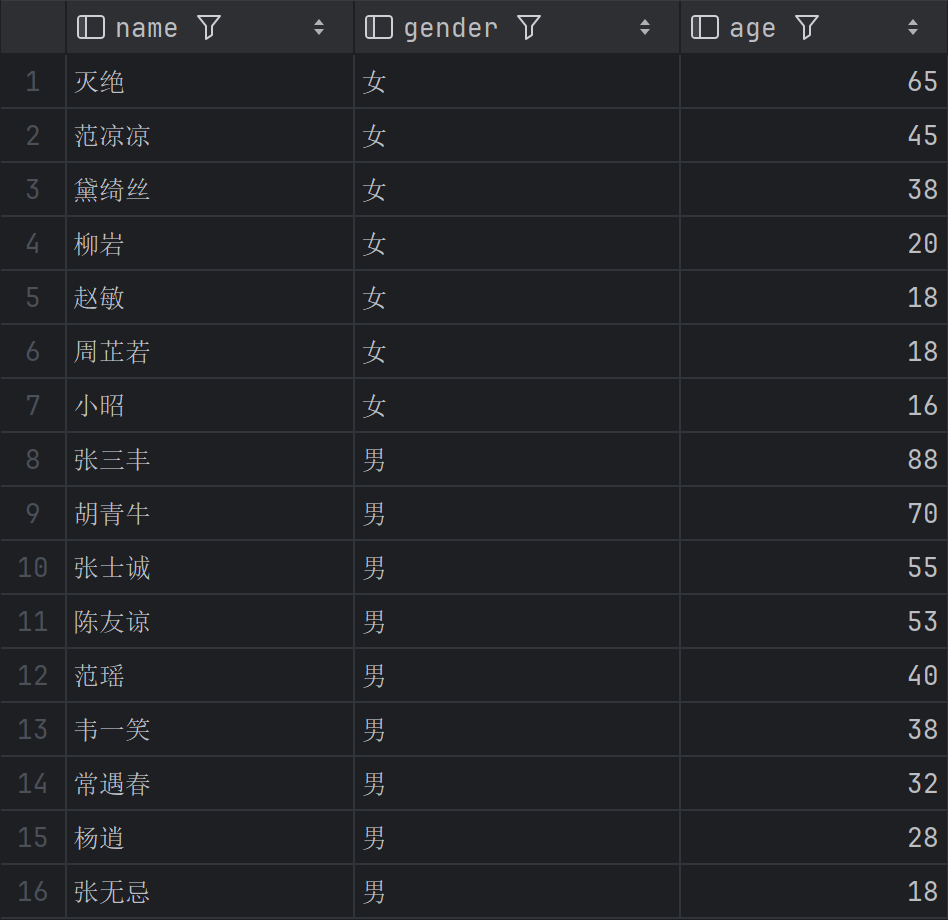
请查询所有员工的姓名、性别和年龄,先按性别升序,再按年龄降序排序
1 | SELECT name, gender, age |
先按
gender排序(比如先女后男,或反过来视数据库编码而定);
性别相同的人,再按age降序排,年纪大的排在前面;
演示了多字段排序和不同排序方式的组合。
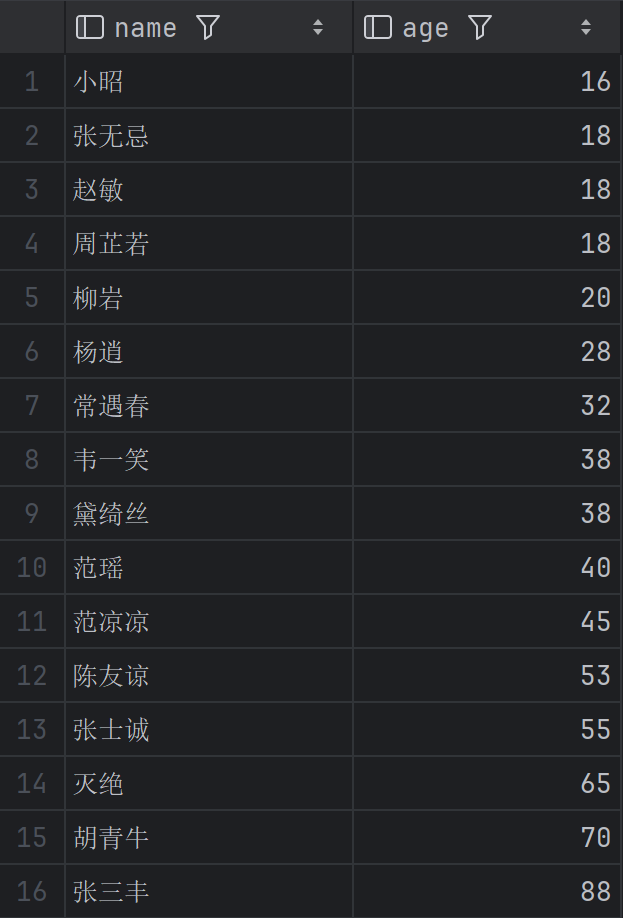
查询所有员工的姓名和入职时间,按入职时间从新到旧排序(最近入职的排前
1 | SELECT name, entrydate |
DESC表示降序;
入职时间越新越靠前。
分页查询 LIMIT
LIMIT 用来限制查询结果的返回行数,通常配合 OFFSET 实现分页。
语法:
SELECT 字段列表 FROM 表名 LIMIT 行数 OFFSET 偏移量;
SELECT 字段列表 FROM 表名 LIMIT 偏移量, 行数;
偏移量从 0 开始计数(第1条记录是索引0),不写默认为0。行数是要返回的行数
MySQL 中可以使用 LIMIT 偏移量, 行数 的方式来简化 LIMIT 行数 OFFSET 偏移量 的写法,两种写法*等价。*
LIMIT 是 MySQL 的语法方言,它是 MySQL(以及 MariaDB、SQLite、PostgreSQL 等部分数据库)支持的非标准 SQL 扩展,不是 SQL 标准语法的一部分。
例题
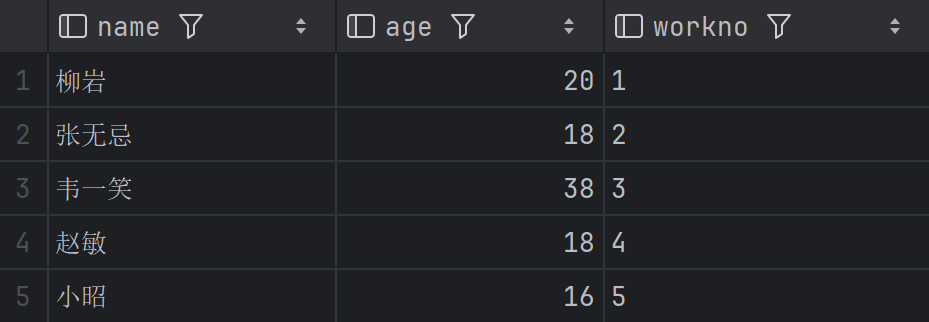
查询 emp 表中前 5 条员工记录,显示 name(姓名)、age(年龄)、workno(工号)
1 | SELECT name, age, workno |
这里只用
LIMIT 行数,表示从第 1 条(索引 0)开始,查 5 条。
假设每页显示 5 条记录,请查询 emp 表的第 2 页数据,显示 id、name、entrydate(入职时间)
1 | SELECT id, name, entrydate |
跳过前 5 条(即第 1 页),从第 6 条开始,查询 5 条(第 2 页)。
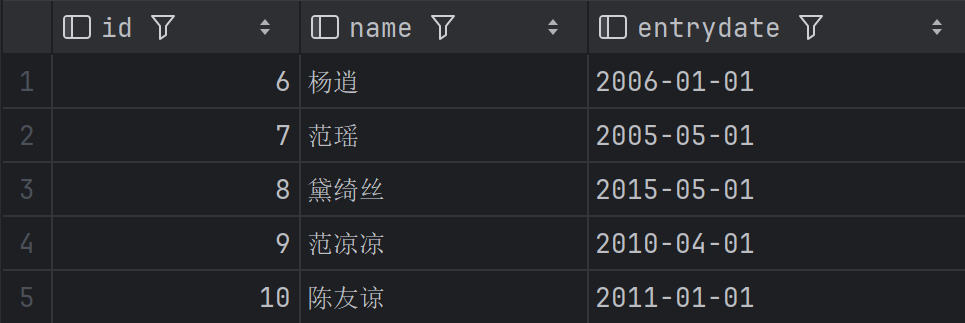
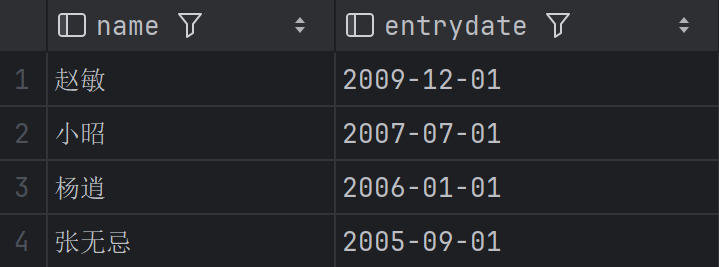
每页显示 4 条记录,按 entrydate 降序排序后,获取第 3 页的员工姓名和入职时间
1 | SELECT name, entrydate |
按入职时间从新到旧排序,跳过前 8 条(第 1、2 页),查第 3 页(4 条)。
DQL编写顺序 & 执行顺序
SELECT语句的编写顺序和执行顺序不同,我们先说编写顺序:
DQL语句的编写顺序
也就是你写 SQL 时的顺序
1 | SELECT 字段列表 |
[]内是可选项
DQL语句的执行顺序
也就是数据库真正处理的顺序
FROM:确定数据来源的表或视图WHERE:对原始数据进行初步筛选GROUP BY:将筛选后的数据进行分组HAVING:对分组后的结果再进行条件过滤SELECT:选出最终要展示的字段(包括聚合函数)ORDER BY:对结果排序LIMIT:限制返回的行数,实现分页等功能
例子
1 | SELECT workaddress, COUNT(*) AS 员工数 |
这条语句的编写顺序和你平常写的一样,但它的执行顺序其实是从 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT。
Fin.
- Title: 【数据库】 DQL - 数据查询语言 Data Query Language (上)
- Author: Yanxiao_xaya
- Created at : 2025-06-07 20:00:30
- Updated at : 2025-06-07 12:11:52
- Link: https://ssxaya.fun/2025/06/07/mysqlDQL/
- License: This work is licensed under CC BY-NC-SA 4.0.